Question
Which of the following algorithms is commonly used in
Machine Learning for clustering tasks?Solution
K-Means is a popular clustering algorithm in machine learning that groups data points into 'k' clusters based on their similarities. The algorithm works by initializing 'k' cluster centroids, assigning each data point to the nearest centroid, and iteratively updating the centroids until the clusters are optimized. K-Means is commonly used in tasks such as market segmentation, image compression, and pattern recognition. Unlike classification algorithms like K-Nearest Neighbors or Logistic Regression, K-Means does not require labeled data.
In this question, a group of numbers/symbols is coded using letters as per the table given below and the conditions which follow. The correct combinatio...
In the following question, select the related letter pair from the given alternatives.
KW : FR :: ?
In a certain language, ADDICT is written as DDATCI. How will JAGUAR be written?
After interchanging the given two signs what will be the values of equation (I) and (II) respectively?
× and ÷
I. 18 ÷ 3 – 4 × 2...
In a certain code language, ‘CONFUSED’ is coded as ‘7’ and ‘CHAIN’ is coded as ‘4’. How will ‘ADULTHOOD’ be coded in that language?<...
Select the correct mirror image of the given figure when the mirror is placed at MN as shown below.
Seven athletes A, B, C, D, E, F and G participate in a race. E is ahead of A but behind F. D is ahead of only two athlete. G is running last. C is runni...
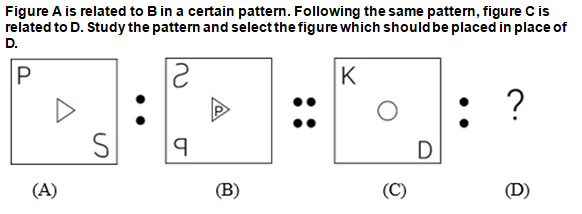
In the given letter-cluster pairs, the first letter-cluster is related to the second letter-cluster following a certain logic. Study the given pairs ca...
CASE : DCVI :: PACK : ?

