Question
What is the primary purpose of data cleaning in the data
analysis process?Solution
Data cleaning focuses on resolving inconsistencies, filling missing values, removing duplicates, and handling outliers to ensure the dataset is accurate, complete, and reliable. High-quality data is critical for generating meaningful insights and avoiding analytical errors. For example, incorrect or incomplete customer information in a sales dataset could lead to flawed marketing strategies. Techniques such as imputation, deduplication, and outlier treatment ensure the dataset is ready for analysis. Clean data enables better decision-making and enhances the credibility of data-driven insights. Why Other Options Are Incorrect: • A: Data transformation involves reformatting or scaling data, not cleaning it. • C: Cleaning prepares data for visualization but is not specifically aimed at visualization. • D: Standardization may occur during cleaning but is not its sole purpose. • E: While validation is related to accuracy, cleaning focuses more broadly on quality improvement.
What will come in place of (?) question mark in the following expression.
(√1296 ÷ √36) × ? = 120
Find the value of ?
{[(864 ÷ 18) ÷ 8] ÷ 3} + 11² – 2³ = ?
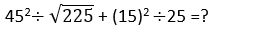
36% of 640 – 12.5% of 352 + 25% of 640 = ? – 48% of 432
Simplify the following expressions and choose the correct option.
(5/9 of 486) + (3/4 of 224) - (25% of 364)
12.5% of (100 + ?) = 40
30% of 8/5 × 5/7 × 2870 =?
(1/5)(40% of 800 – 120) = ? × 5
Simplify the expression:
(5x + 15) / (x² + 3x)
116 x (2/3)% of 420 + 666 x (2/3)% of 186 = 457 x (1/7)% of 126 + 555 x (5/9)% of 198 + ?

