Question
If G is made to face the opposite direction, who would
sit on his immediate left? Study the following information carefully to answer these questions carefully. A, B, C, D, E, F, G and H are sitting around a square table in such a way that four of them sit at four corner of the square while four sit in the middle of each of the four sides. The ones who sit at the four corners face outside while those who sit in the middle of the sides face the centre of the table. D sits third to the right of G. G faces the centre. E sits third to the left of C. C does not sit in the middle of the sides. Only one person sits between E and F. F is not an immediate neighbour of C. H faces the centre. A, is not an immediate neighbour of F.Solution
We have provided with the information, D sits third to the right of G. G faces the centre . E sits third to the left of C. C does not sit in the middle of the sides. C can sit at two places either on the immediate left of G or at the immediate right of G. Case. 1 – When C sits on the immediate right of G 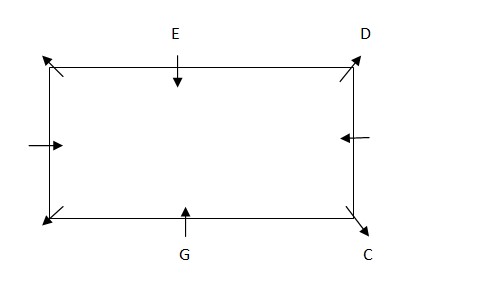 Case.2 – When C sits on the immediate left of G
Case.2 – When C sits on the immediate left of G 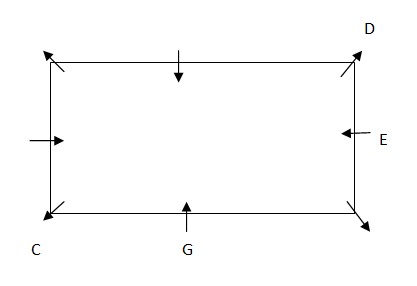 Only one person sits between E and F. F is not an immediate neighbour of C. Case 1- F will sit on the right of E. H faces the centre. A, is not an immediate neighbour of F.
Only one person sits between E and F. F is not an immediate neighbour of C. Case 1- F will sit on the right of E. H faces the centre. A, is not an immediate neighbour of F. 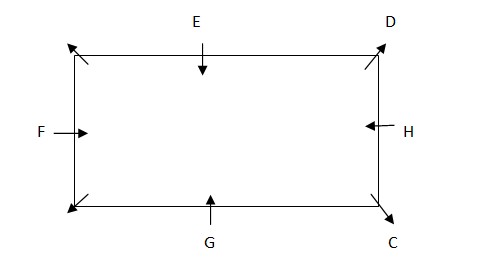 In this case A will become an immediate neighbour of F which will make this case wrong. We will continue with case 2. Case 2- F will sit on the right of E. Only place left for B is on immediate right of F. Thus the final arrangement is;
In this case A will become an immediate neighbour of F which will make this case wrong. We will continue with case 2. Case 2- F will sit on the right of E. Only place left for B is on immediate right of F. Thus the final arrangement is; 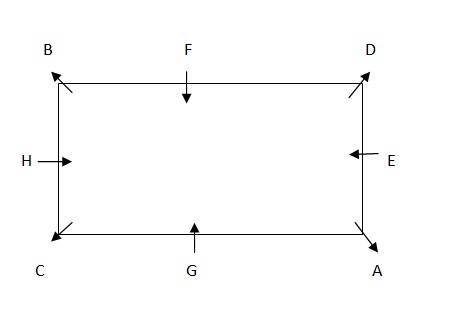
Which of the following is a supervised learning technique?
Which measure of central tendency is most appropriate when data has extreme outliers?
Which sampling technique is most suitable when a population has distinct subgroups that should be represented proportionally?
Which of the following is an example of semi-structured data ?
Consider the following Python code snippet:
class Employee:
def __init__(self, name, age):
self.name = name
<...What is polymorphism in Python?
Which of the following best describes non-random sampling?
Which of the following is the correct decomposition of time series data into its components?
Which of the following is the primary purpose of exploratory data analysis (EDA)?
Which of the following statements about asymmetric encryption is true?

